Concepts
Embeddings are core to many AI and vector applications. This guide covers these concepts. If you prefer to get started right away, see our guide on Generating Embeddings.
What are embeddings?
Embeddings capture the "relatedness" of text, images, video, or other types of information. This relatedness is most commonly used for:
- Search: how similar is a search term to a body of text?
- Recommendations: how similar are two products?
- Classifications: how do we categorize a body of text?
- Clustering: how do we identify trends?
Let's explore an example of text embeddings. Say we have three phrases:
- "The cat chases the mouse"
- "The kitten hunts rodents"
- "I like ham sandwiches"
Your job is to group phrases with similar meaning. If you are a human, this should be obvious. Phrases 1 and 2 are almost identical, while phrase 3 has a completely different meaning.
Although phrases 1 and 2 are similar, they share no common vocabulary (besides "the"). Yet their meanings are nearly identical. How can we teach a computer that these are the same?
Human language
Humans use words and symbols to communicate language. But words in isolation are mostly meaningless - we need to draw from shared knowledge & experience in order to make sense of them. The phrase “You should Google it” only makes sense if you know that Google is a search engine and that people have been using it as a verb.
In the same way, we need to train a neural network model to understand human language. An effective model should be trained on millions of different examples to understand what each word, phrase, sentence, or paragraph could mean in different contexts.
So how does this relate to embeddings?
How do embeddings work?
Embeddings compress discrete information (words & symbols) into distributed continuous-valued data (vectors). If we took our phrases from before and plot them on a chart, it might look something like this:
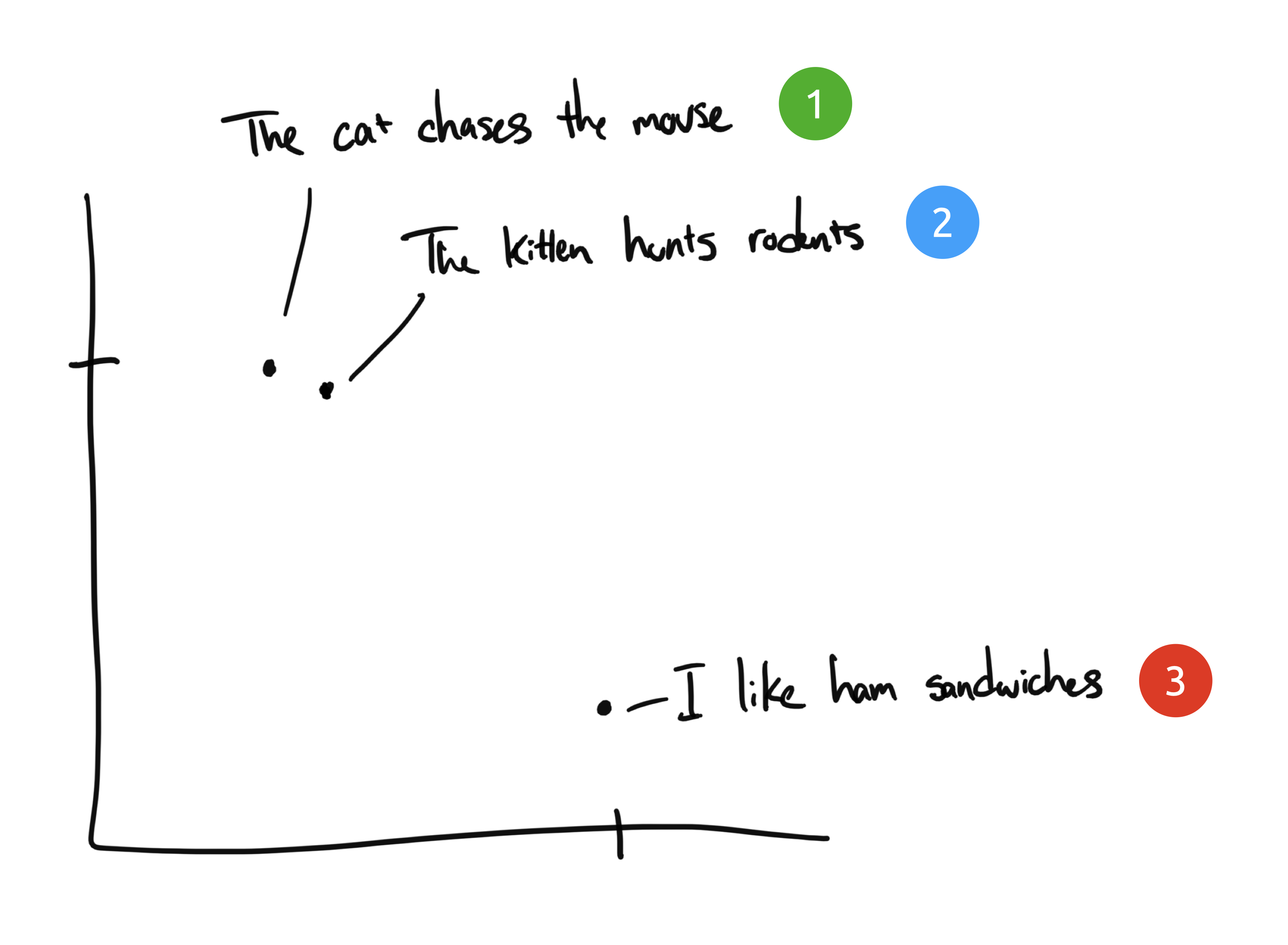
Phrases 1 and 2 would be plotted close to each other, since their meanings are similar. We would expect phrase 3 to live somewhere far away since it isn't related. If we had a fourth phrase, “Sally ate Swiss cheese”, this might exist somewhere between phrase 3 (cheese can go on sandwiches) and phrase 1 (mice like Swiss cheese).
In this example we only have 2 dimensions: the X and Y axis. In reality, we would need many more dimensions to effectively capture the complexities of human language.
Using embeddings
Compared to our 2-dimensional example above, most embedding models will output many more dimensions. For example the open source gte-small model outputs 384 dimensions.
Why is this useful? Once we have generated embeddings on multiple texts, it is trivial to calculate how similar they are using vector math operations like cosine distance. A common use case for this is search. Your process might look something like this:
- Pre-process your knowledge base and generate embeddings for each page
- Store your embeddings to be referenced later
- Build a search page that prompts your user for input
- Take user's input, generate a one-time embedding, then perform a similarity search against your pre-processed embeddings.
- Return the most similar pages to the user